
Hi! I am a final year PhD student at Robotics Institute of Carnegie Mellon University, advised by Prof. Deva Ramanan. I did my undergrad in Computer Science and Maths at Cornell University and served as college symbol bearer (top 5 of the college). My current research focuses on computer vision and language, especially evaluating and improving multimodal generative models.
🔥 News
- 2026.04: CHAI was accepted to CVPR’26 as a Highlight (Top 3%)! An 8B model beating GPT-5 and Gemini-3.1-Pro on professional video captioning.
- 2025.09: CameraBench was accepted to NeurIPS’25 (Spotlight).
- 2024.09: NaturalBench was accepted to NeurIPS’24.
- 2024.08: VQAScore was accepted to ECCV’24. In addition, VQAScore is highlighted in Google’s Imagen3 Technical Report as the strongest replacement for CLIPScore, with Imagen3 achieving SOTA on GenAI-Bench for compositional text-to-visual generation.
- 2024.06: GenAI-Bench won Best Short Paper Award at SynData@CVPR2024!
- 2024.05: VisualGPTScore was accepted to ICML’24.
- 2024.04: We introduced VQAScore for evaluating the prompt alignment of text-to-image/video/3D models: Evaluating Text-to-Visual Generation with Image-to-Text Generation.
- 2024.02: Two papers accepted to CVPR’24: Language Models as Black-Box Optimizers for Vision-Language Models and The Neglected Tails of Vision-Language Models.
- 2023.12: Finished my internship at Meta GenAI. Many thanks to my great mentors Pengchuan Zhang and Xide Xia!
- 2023.09: My recent work Revisiting the Role of Language Priors in Vision-Language Models demonstrates top-tier performance across retrieval benchmarks like ARO/SugarCrepe/Winoground.
- 2023.02: Multimodality Helps Unimodality: Cross-Modal Few-Shot Learning with Multimodal Models was accepted by CVPR’23.
- 2022.09: LECO: Continual Learning with Evolving Class Ontologies was accepted by NeurIPS’22. Check out the website and slides for a quick overview!
- 2022.06: The 1st CLEAR Challenge was hosted on CVPR’22 2nd Workshop on Open World Vision. Check out the slides for a quick overview!
- 2021.09: The CLEAR Benchmark: Continual LEArning on Real-World Imagery accepted by NeurIPS’21.
- 2020.06: Best Paper Nomination at CVPR’20 for Visual Chirality!
📝 Publications
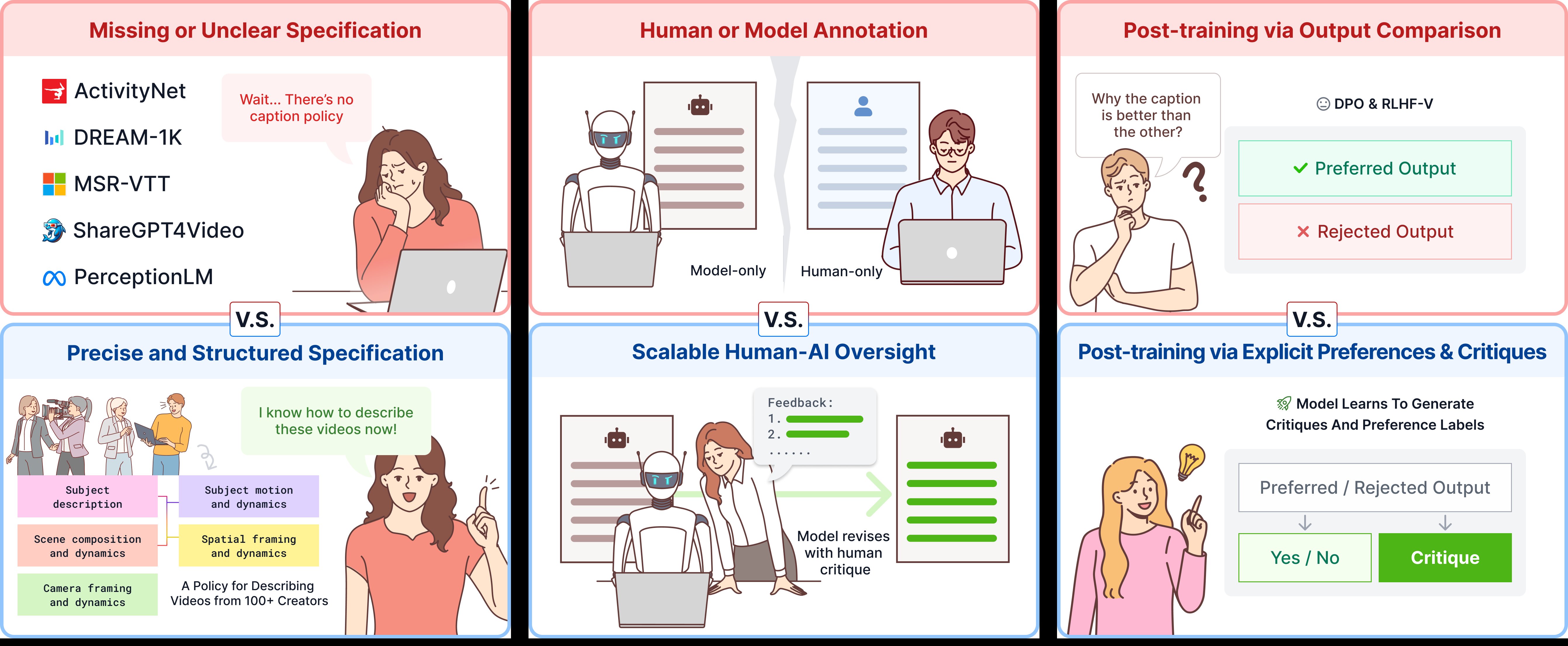
CHAI: Building a Precise Video Language with Human-AI Oversight (CVPR’26 Highlight, Top 3%)
Zhiqiu Lin, Chancharik Mitra, Siyuan Cen, Isaac Li, Yuhan Huang, Yu Tong Tiffany Ling, Hewei Wang, Irene Pi, Shihang Zhu, Ryan Rao, George Liu, Jiaxi Li, Ruojin Li, Yili Han, Yilun Du, Deva Ramanan
- Before AI can generate professional videos, it needs to see like a professional. We spent a year with 100+ content creators building the shared language of cinema for AI.
- A structured video specification grounded by 200+ visual primitives across subjects, scenes, motion, spatial framing, and camera dynamics.
- Critique-based Human-AI oversight (CHAI): AI drafts fluent captions, humans critique visual errors — each doing what they’re best at.
- Post-training on CHAI triplets lets our 8B Qwen3-VL surpass GPT-5 and Gemini-3.1-Pro on captioning, reward modeling, and critique generation.
- Unlocks professional-grade video generation — fine-tuned Wan follows 400-word cinematic prompts for dolly zooms, rack focus, speed ramps, Dutch angles, and more.
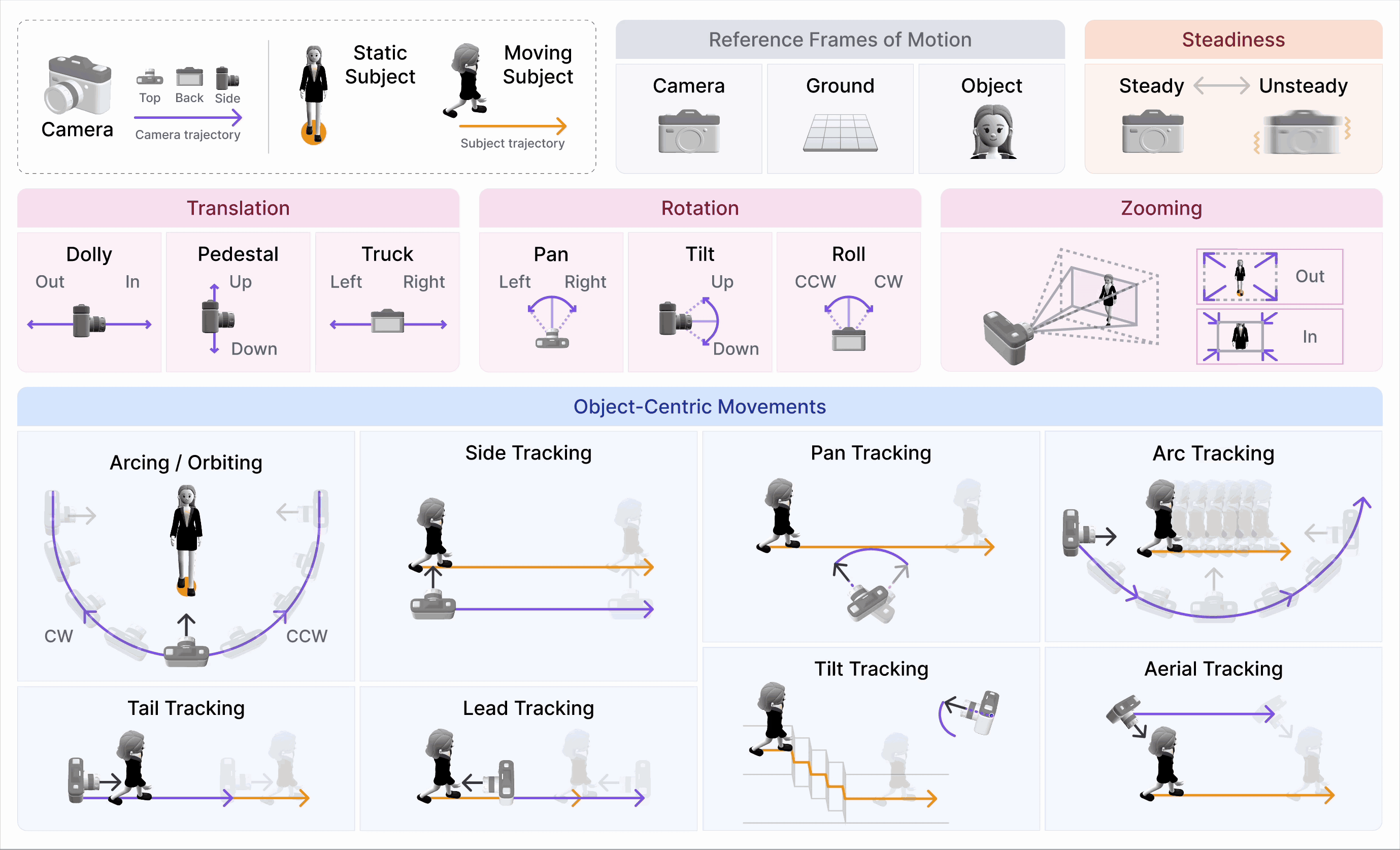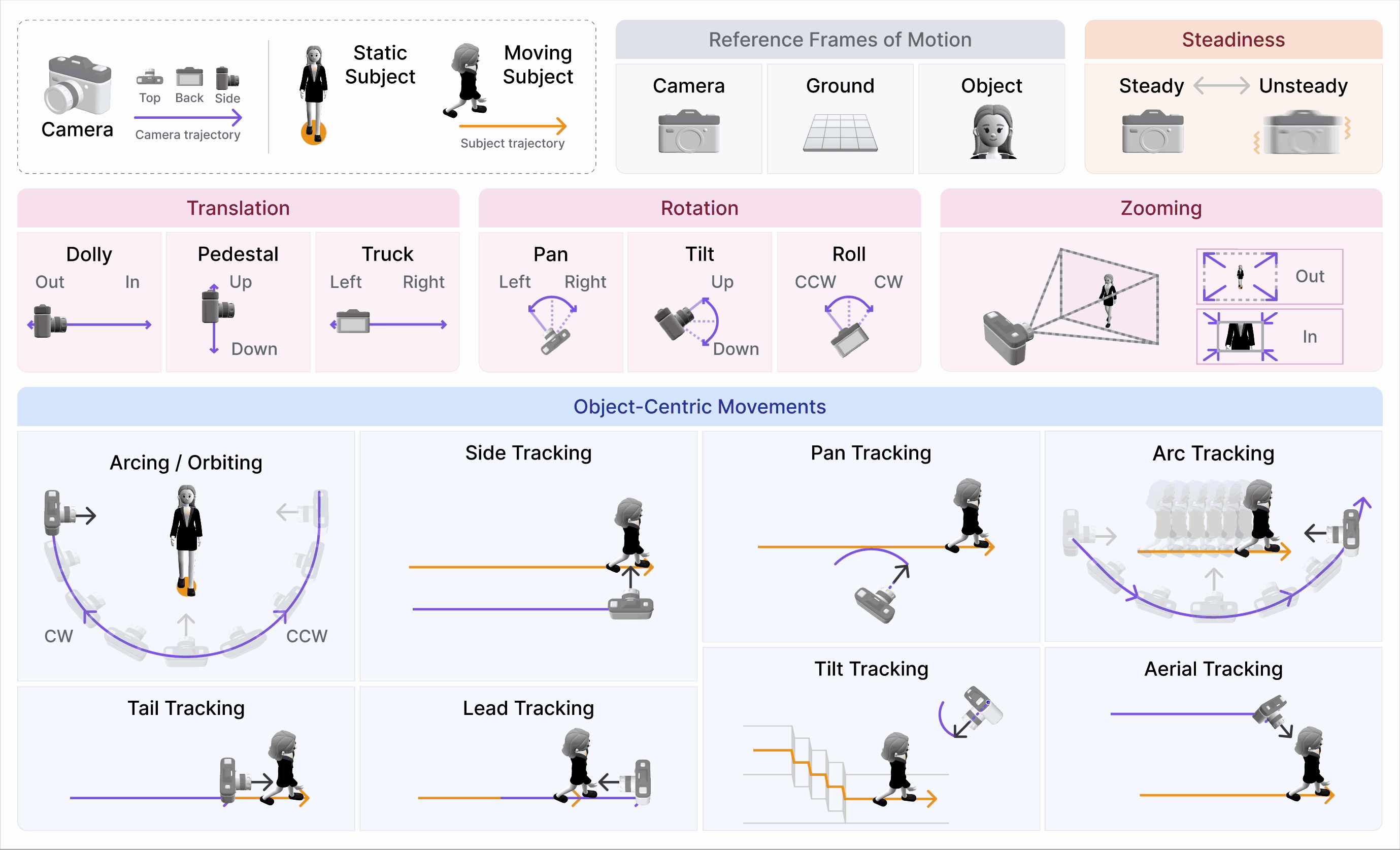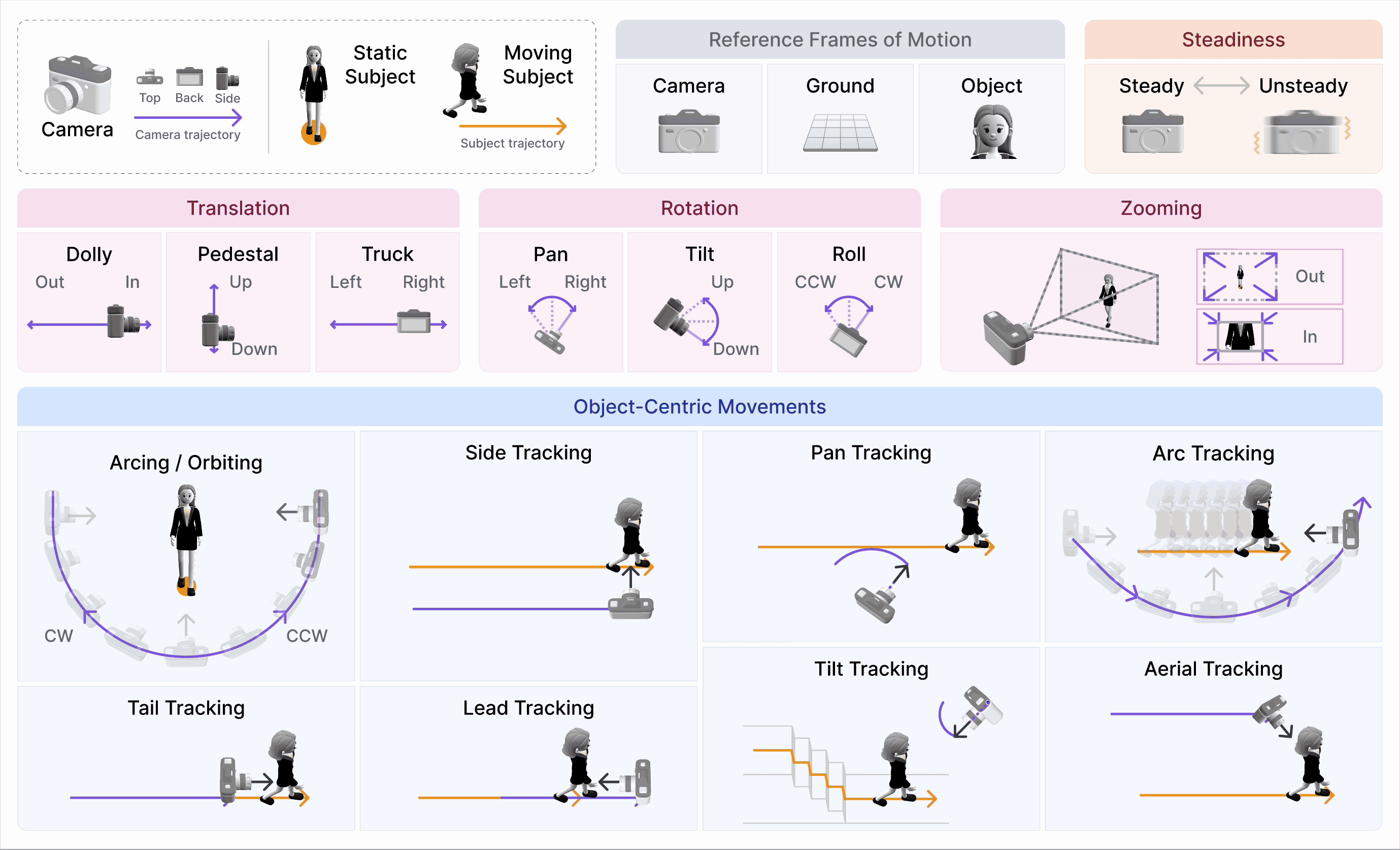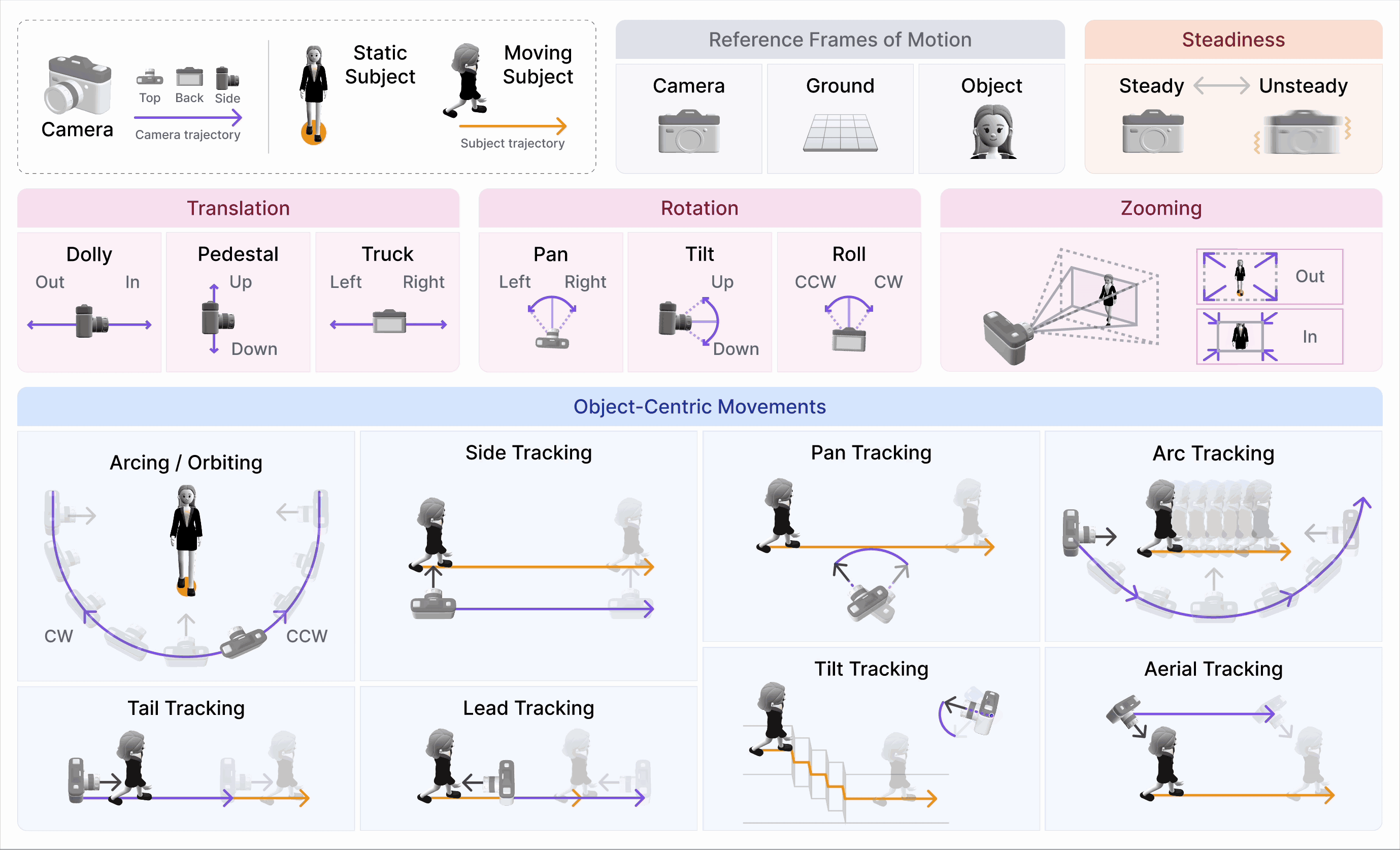
CameraBench: Towards Understanding Camera Motions in Any Video (NeurIPS’25 Spotlight, Top 3%)
Zhiqiu Lin*, Siyuan Cen*, Daniel Jiang, Jay Karhade, Hewei Wang, Chancharik Mitra, Yu Tong Tiffany Ling, Yuhan Huang, Sifan Liu, Mingyu Chen, Rushikesh Zawar, Xue Bai, Yilun Du, Chuang Gan, Deva Ramanan

- We introduce CameraBench, a large-scale effort that pushes video-language models to reason about the language of camera motion just like professional cinematographers.
- Our open-source dataset and models are gaining strong interest and adoption from frontier video understanding and generation labs such as Deepmind, xAI, and Kling.
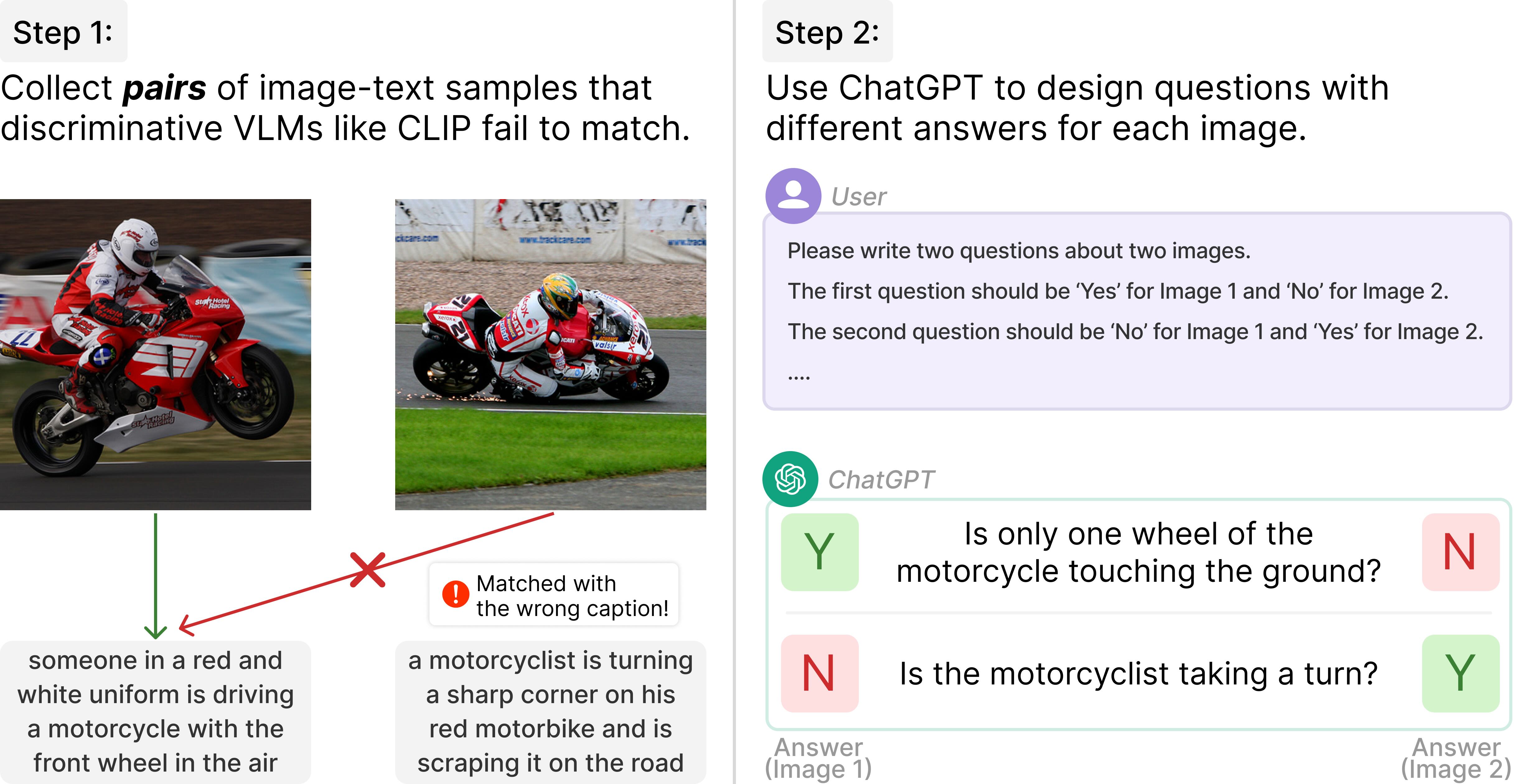
NaturalBench: Evaluating Vision-Language Models on Natural Adversarial Samples (NeurIPS’24)
Zhiqiu Lin*, Baiqi Li*, Wenxuan Peng*, Jean de Nyandwi*, Zixian Ma, Simran Khanuja, Ranjay Krishna*, Graham Neubig*, Deva Ramanan*

- We present NaturalBench, a vision-centric VQA benchmark with simple questions about natural images that humans find easy but significantly challenge state-of-the-art models like GPT-4o, Molmo, Llama3.2, LLaVA-OneVision, and Qwen2-VL.
- We show that debiasing can nearly double model performance, even for GPT-4o!
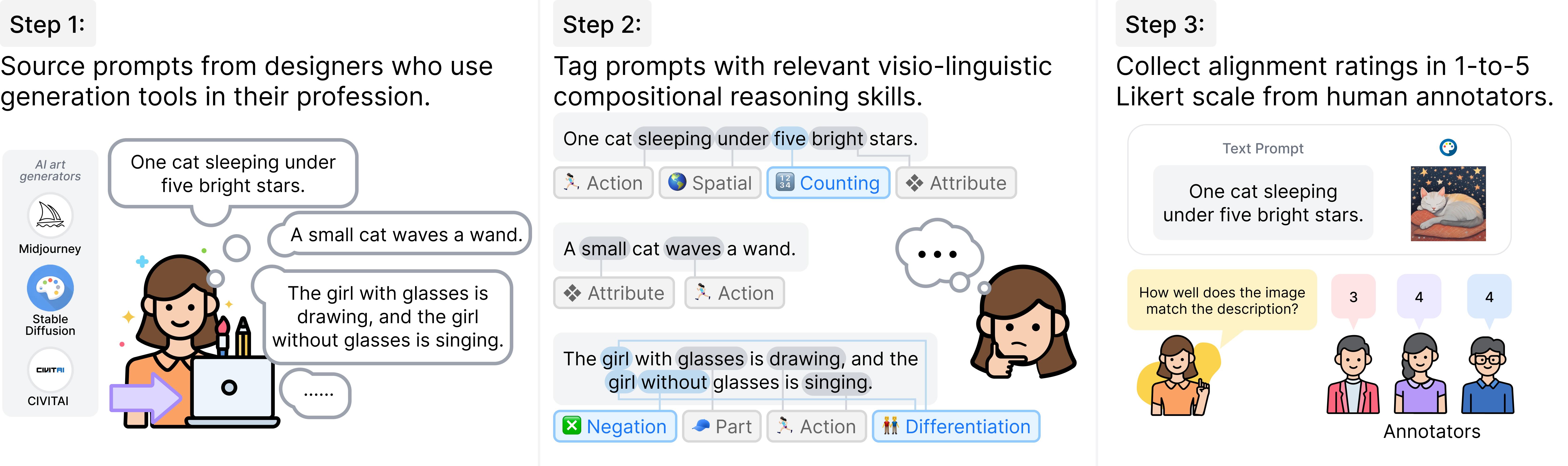
GenAI-Bench: Evaluating and Improving Compositional Text-to-Visual Generation (CVPR’24, Best Short Paper at SynData Workshop)
Zhiqiu Lin*, Baiqi Li*, Deepak Pathak, Emily Li, Yixin Fei, Kewen Wu, Xide Xia*, Pengchuan Zhang*, Graham Neubig*, Deva Ramanan*
- We propose GenAI-Bench, a comprehensive benchmark for compositional text-to-visual generation collected by professional designers.
- We release over 80,000 human ratings to support future evaluation of automated metrics.
- We show that VQAScore can be used to improve black-box generative models such as DALL-E 3!
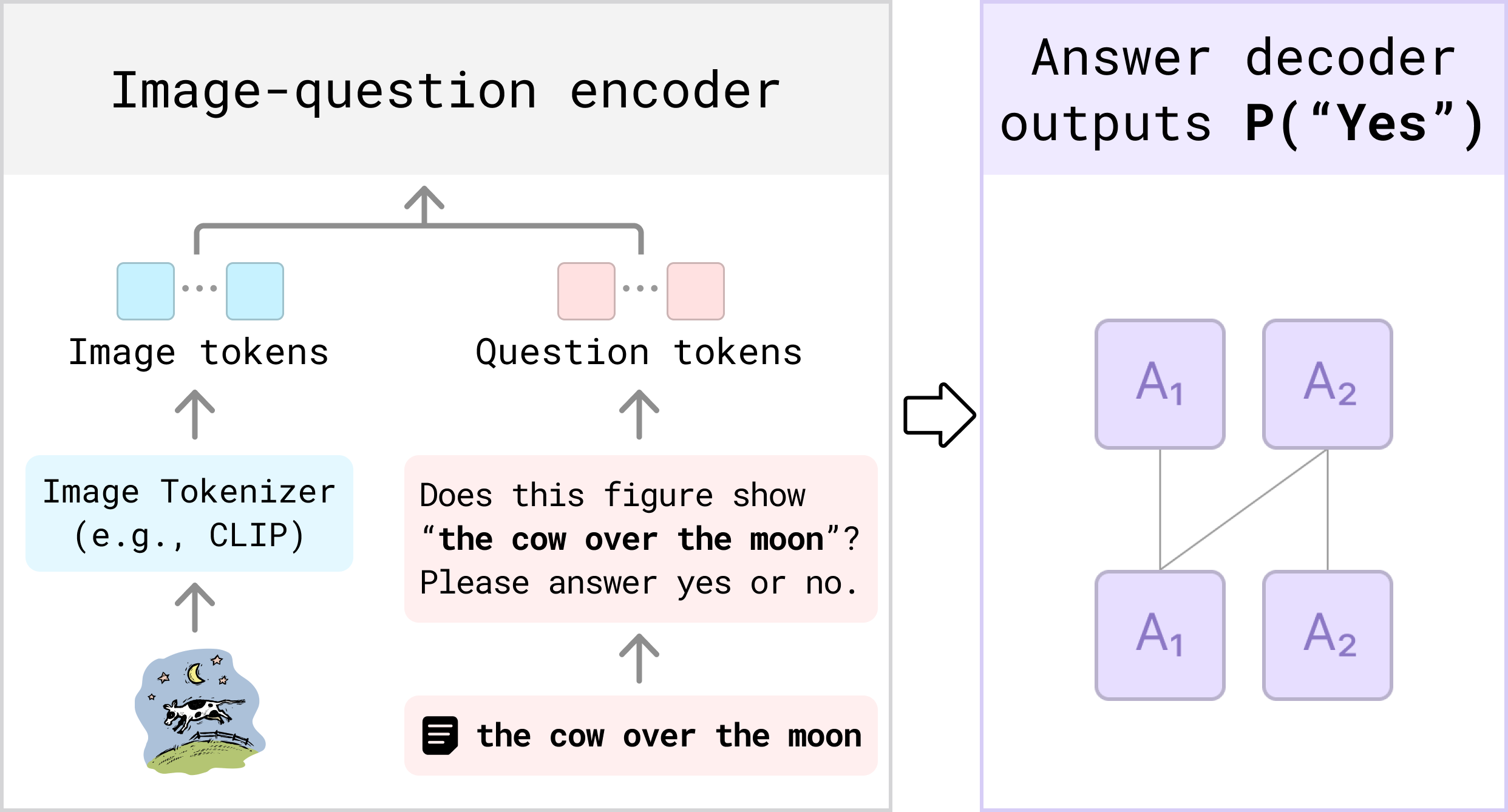
Evaluating Text-to-Visual Generation with Image-to-Text Generation (ECCV’2024)
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Emily Li, Xide Xia, Graham Neubig, Pengchuan Zhang*, Deva Ramanan*

- We propose VQAScore, the state-of-the-art alignment metric for text-to-image/video/3D models.
- VQAScore based on our new CLIP-FlanT5 model outperforms previous metrics based on GPT-4Vision or costly human feedback.
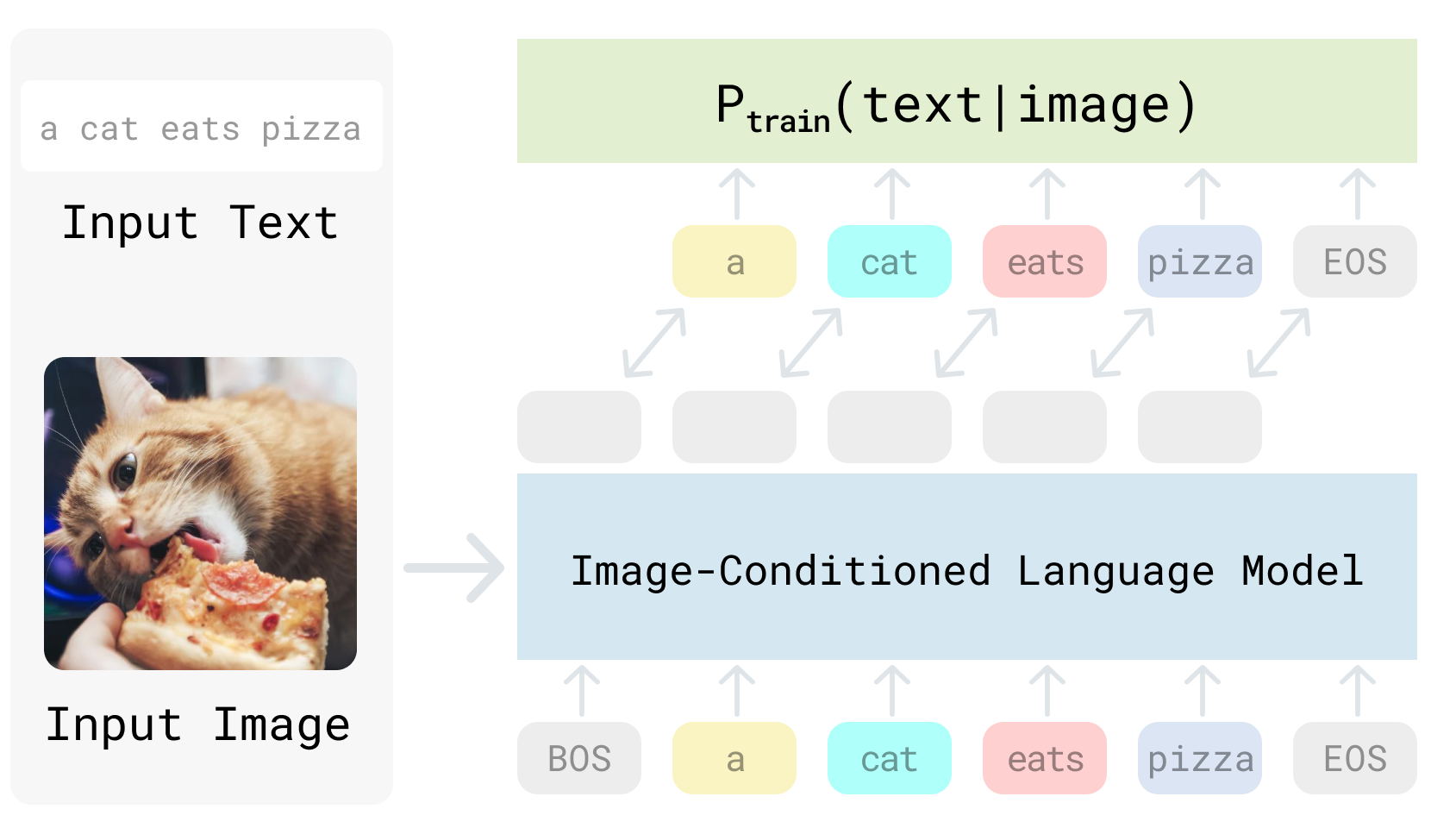
Revisiting the Role of Language Priors in Vision-Language Models (ICML’24)
Zhiqiu Lin*, Xinyue Chen*, Deepak Pathak, Pengchuan Zhang, Deva Ramanan
- We use generative VLMs to implement Visual Generative Pre-Training Score (VisualGPTScore), i.e., the probablity score of generating a text given an image.
- Such a generative score achieves top-tier image-text retrieval performance on multiple compositionality benchmarks, surpassing all discriminative approaches by a great margin.
- We further investigate the role of language prior P(text) through a probablistic lens, and introduce a debiasing solution that consistently improves the VisualGPTScore under train-test distribution shifts over text.
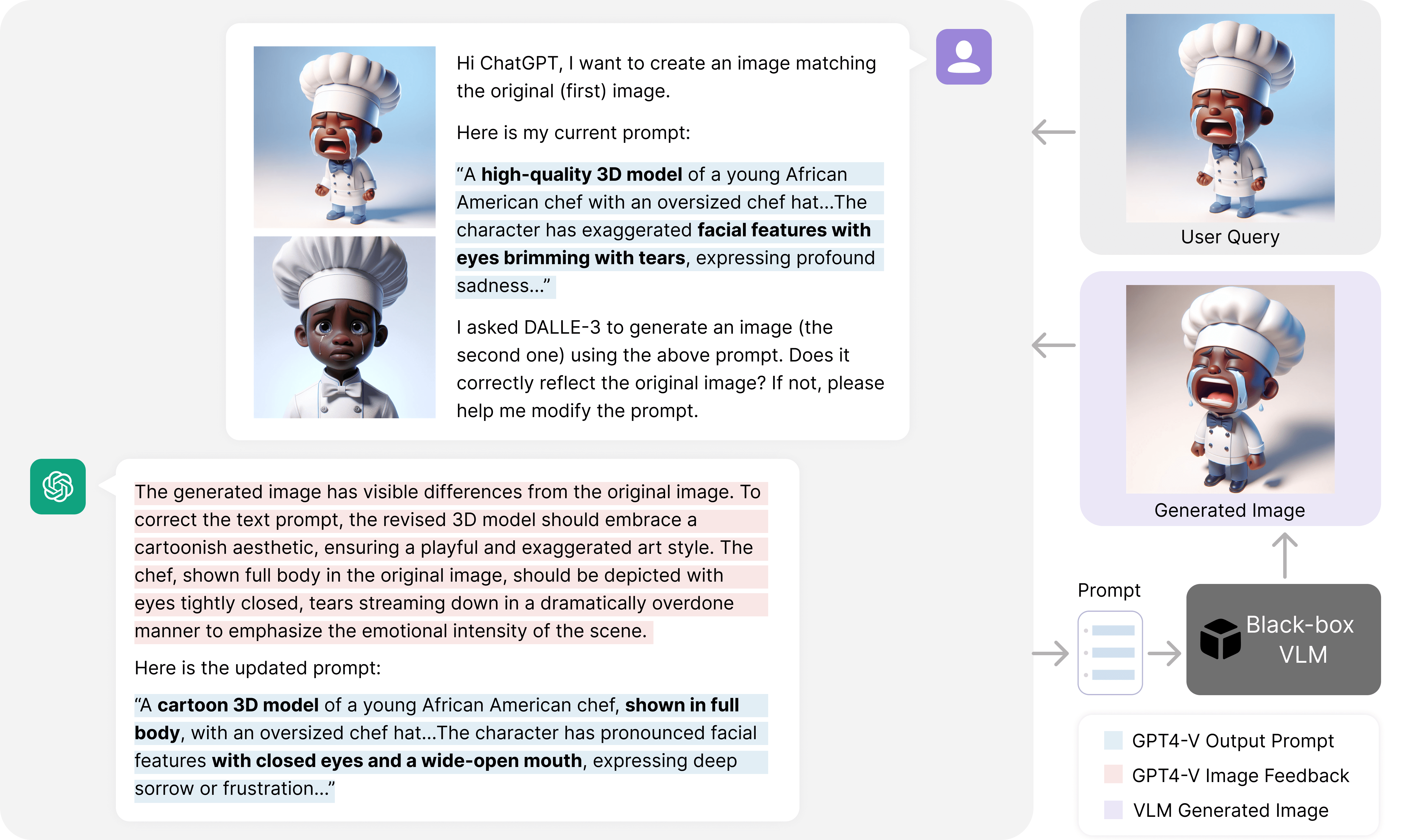
Language Models as Black-Box Optimizers for Vision-Language Models (CVPR’24)
Zhiqiu Lin*, Shihong Liu*, Samuel Yu*, Ryan Lee, Tiffany Ling, Deepak Pathak, Deva Ramanan
- We use ChatGPT to effectively optimize vision-language models without white-box access to model weights or gradients.
- We show successful applications in visual classification, text-to-image generation and personalization.

The Neglected Tails of Vision-Language Models (CVPR’24)
Zhiqiu Lin*, Shubham Parashar*, Tian Liu*, Xiangjue Dong, Yanan Li, Deva Ramanan, James Caverlee, Shu Kong
- Popular vision-language models (CLIP, MetaCLIP, OpenCLIP) are all long-tailed learners trained on drastically imbalanced web data, causing biases in downstream applications such as visual chatbots (GPT-4Vision) and T2I generation (Stable Diffusion, DALL-E 3).
- We fix these biases through our SOTA prompting and retrieval-augmented strategies.
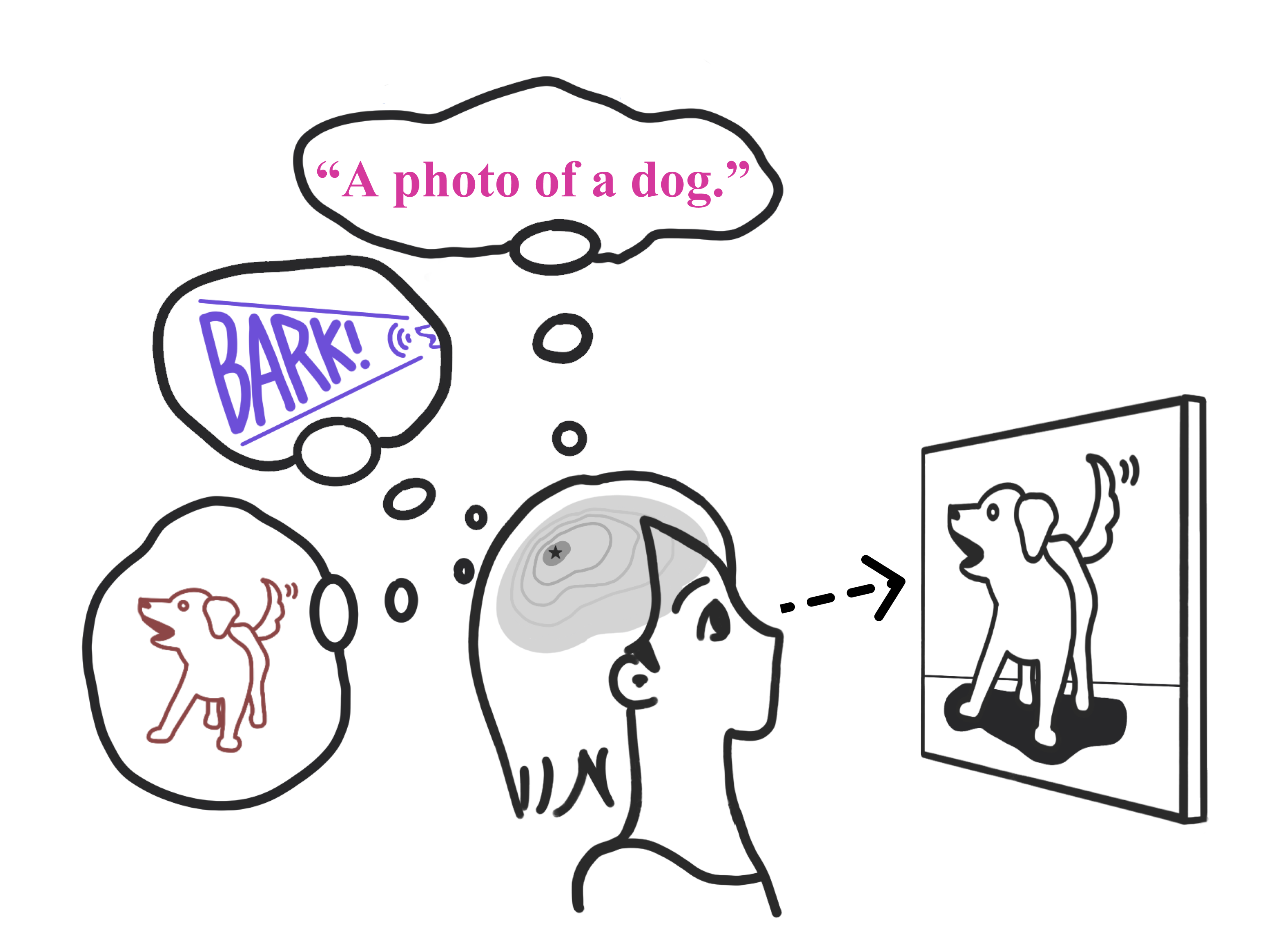
Multimodality Helps Unimodality: Cross-Modal Few-Shot Learning with Multimodal Models (CVPR’23)
Zhiqiu Lin*, Samuel Yu*, Zhiyi Kuang, Deepak Pathak, Deva Ramanan

- We propose a simple cross-modal adaptation method for multimodal models that repurposes information from other modalities (e.g., class names and audio clips) as additional training samples.
- For CLIP, it achieves SOTA few-shot adaptation performance even with a simple linear probe, and consistently improves prior art such as prompting, adapter, and weight ensembling.
- Audiovisual experiments with AudioCLIP suggest that one can learn a better dog visual classifier by listening to them bark.
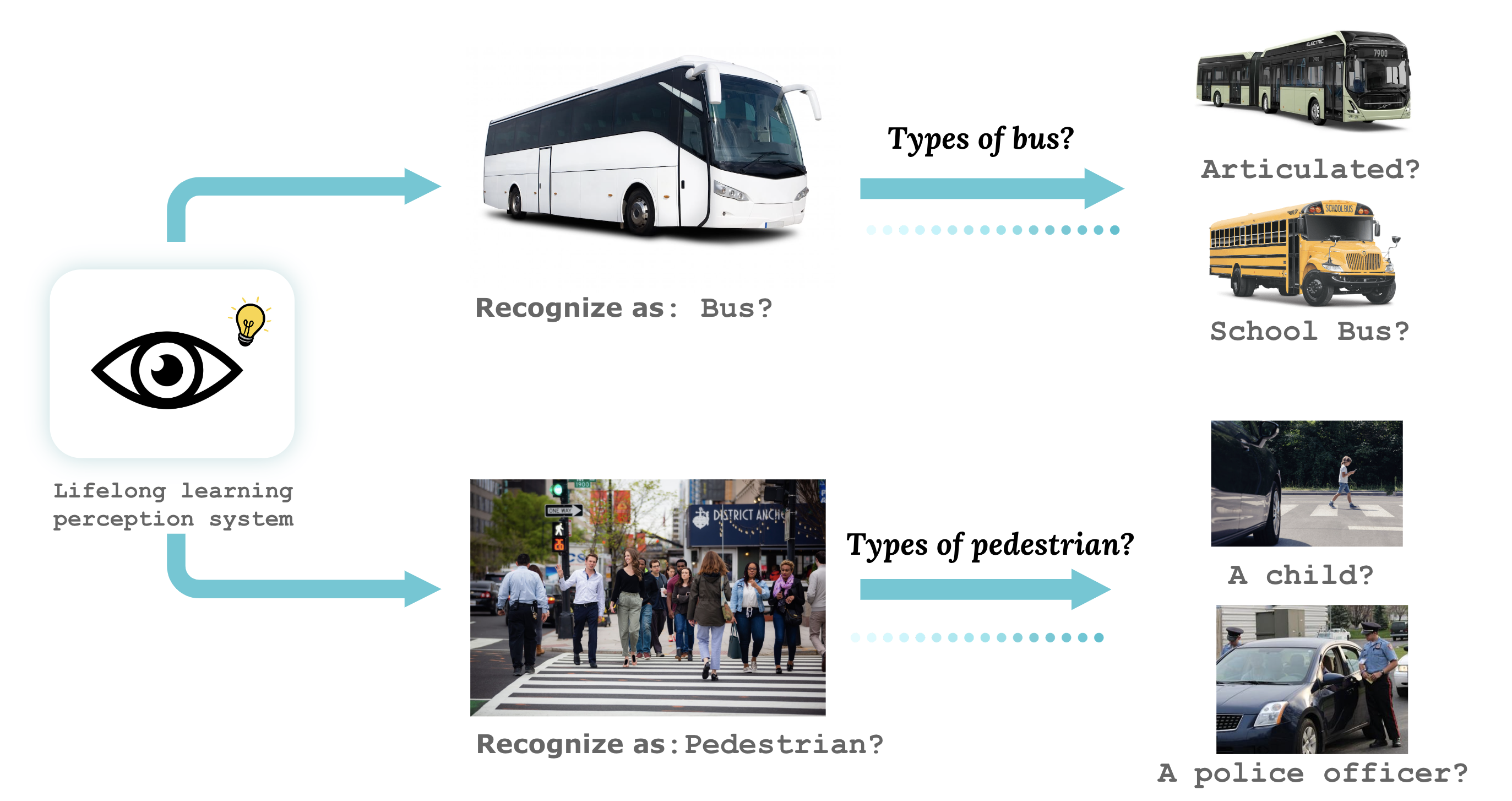
LECO: Continual Learning with Evolving Class Ontologies (NeurIPS’22)
Zhiqiu Lin, Deepak Pathak, Yu-Xiong Wang, Deva Ramanan*, Shu Kong*
Website | Arxiv | NeurIPS’22 Talk
- A practical lifelong vision benchmark motivated by real-world dataset versioning issues, e.g., Mapillary 1.2 to 2.0.
- Simple but effective solutions such as joint training, semi-supervised learning, and learning-with-partial-labels to address inconsistent annotation (both coarse-grained and fine-grained).
The CLEAR Benchmark: Continual LEArning on Real-World Imagery (NeurIPS’21)
Zhiqiu Lin, Jia Shi, Deepak Pathak*, Deva Ramanan*
CLEAR Wiki | NeurIPS Paper Site | Arxiv | CVPR’22 Talk
- The first continual benchmark for visual recognition with natural distribution shifts over a decade!
- CLEAR has a 10- and 100-classes version (download links), similar to the famous CIFAR-10 and CIFAR-100 benchmarks.
- 1st CLEAR challenge was hosted on June 19th, 2022. We have 79 participants from 21 different countries and regions signed up for the challenge!

- QPyTorch: A Low-Precision Arithmetic Simulation Framework.
Tianyi Zhang, Zhiqiu Lin, Guandao Yang, Chris De Sa, NeurIPS 2019 Workshop @ EMC2 |
- What.Hack: Engaging Anti-Phishing Training Through a Role-playing Cyber Defense Simulation Game. Zikai Alex Wen, Zhiqiu Lin, Rowena Chen, Erik Andersen, CHI 2019

🎖 Honors and Awards
- 2026.03 CVPR 2026 Highlight (Top 3%) for CHAI!
- 2025.09 NeurIPS 2025 Spotlight for CameraBench!
- 2024.06 Best Short Paper Award at SynData@CVPR’24 for GenAI-Bench!
- 2020.06 Best Paper Nomination at CVPR’20 for Visual Chirality!
- 2020.05 Graduated Summa Cum Laude in Computer Science and Mathematics from Cornell University, and served as college symbol bearer (top 5 of the college).
📖 Educations
- 2020.09 - (now), PhD student, Carnegie Mellon University.
- 2016.09 - 2020.06, Undergraduate, Cornell University.
💬 Invited Talks
- 2026.06-07, I presented Scalable Oversight Across Generative Visual AI: Toward Visual Storytelling for Everyone at Sooth Labs (thanks Russ Salakhutdinov for inviting me and Yaser Sheikh for hosting!) and Runway (thanks Jimei Yang for inviting me!).
- 2024.10-11, I presented Evaluating and Improving Vision-Language Generative Models at the Princeton Visual AI Lab and Cornell University (thanks Xindi Wu and CUAI for inviting me!).
- 2024.06, I presented GenAI-Bench Benchmark at the CVPR’24 Workshop on Synthetic Data.
- 2022.06, I presented CLEAR Benchmark at the CVPR’22 2nd Workshop on Open World Vision.
💻 Services
- Organizer: CVPR’22 VPLOW Workshop (Challenge Track)
- Reviewer: ECCV, CVPR (Outstanding reviewer), ICCV, NeurIPS, ICML.
- Teaching (CMU): Learning-based Image Synthesis and Advanced Computer Vision
- Teaching (Cornell): Advanced Machine Learning, Cornell Tech Pre-Master Program, Functional Programming, Algorithm Analysis, Data Structures, Computer Vision