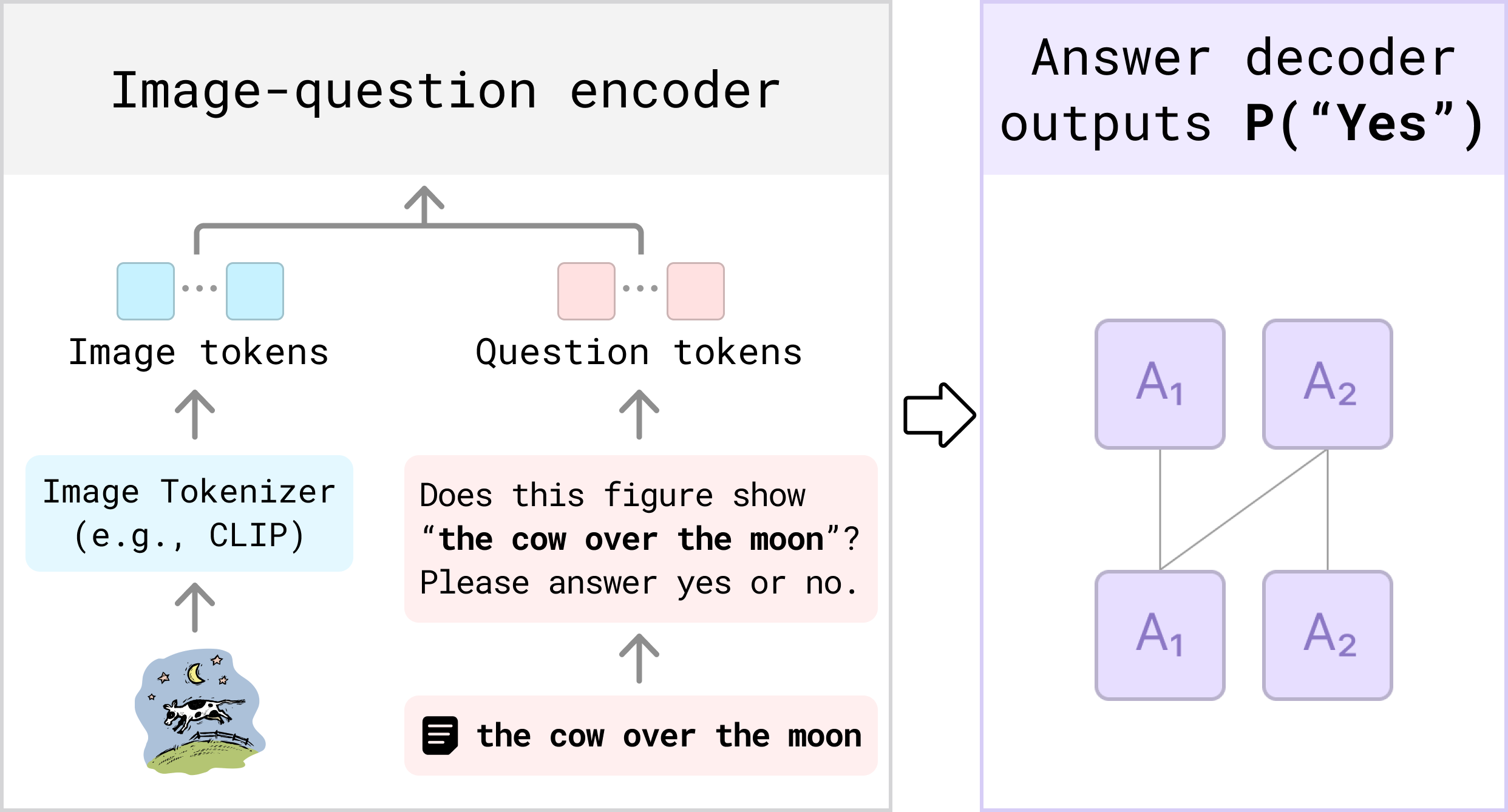
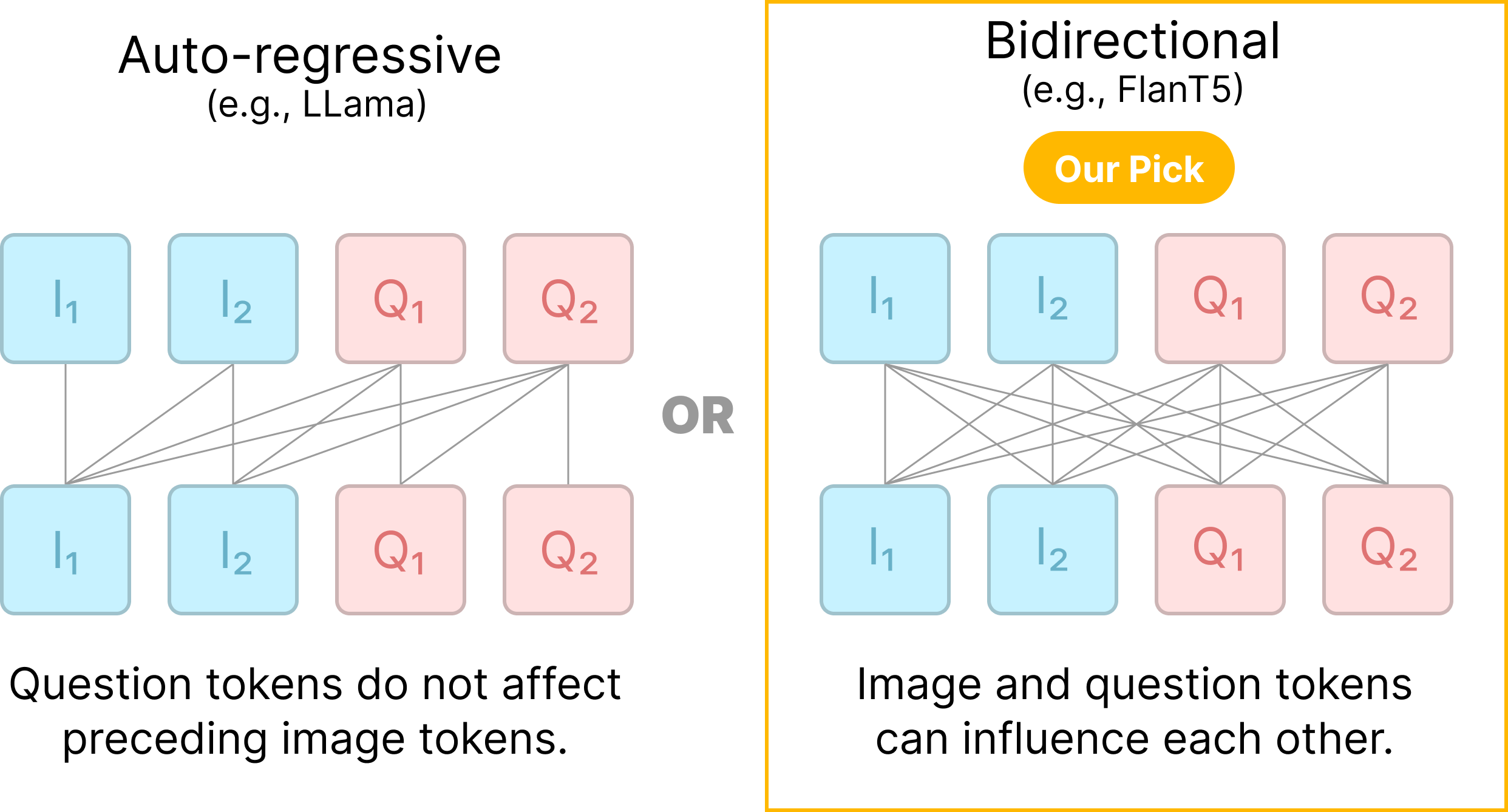
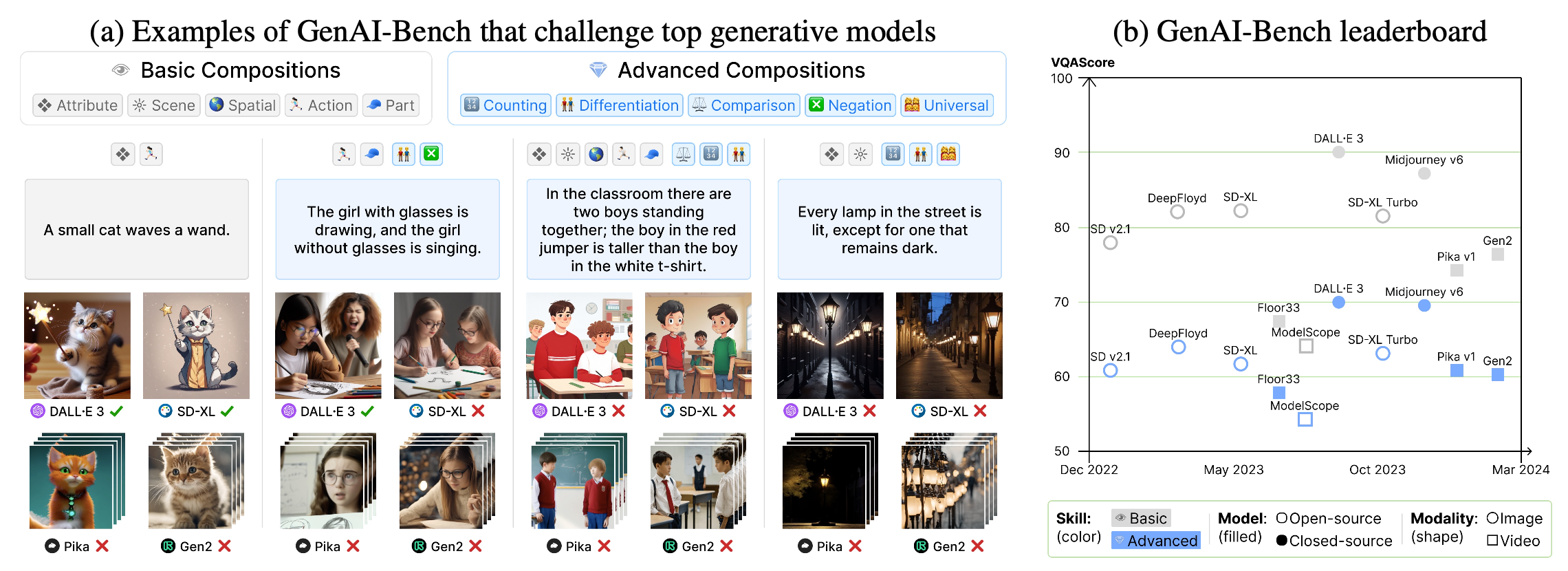
VQAScore for Text-to-Visual Evaluation
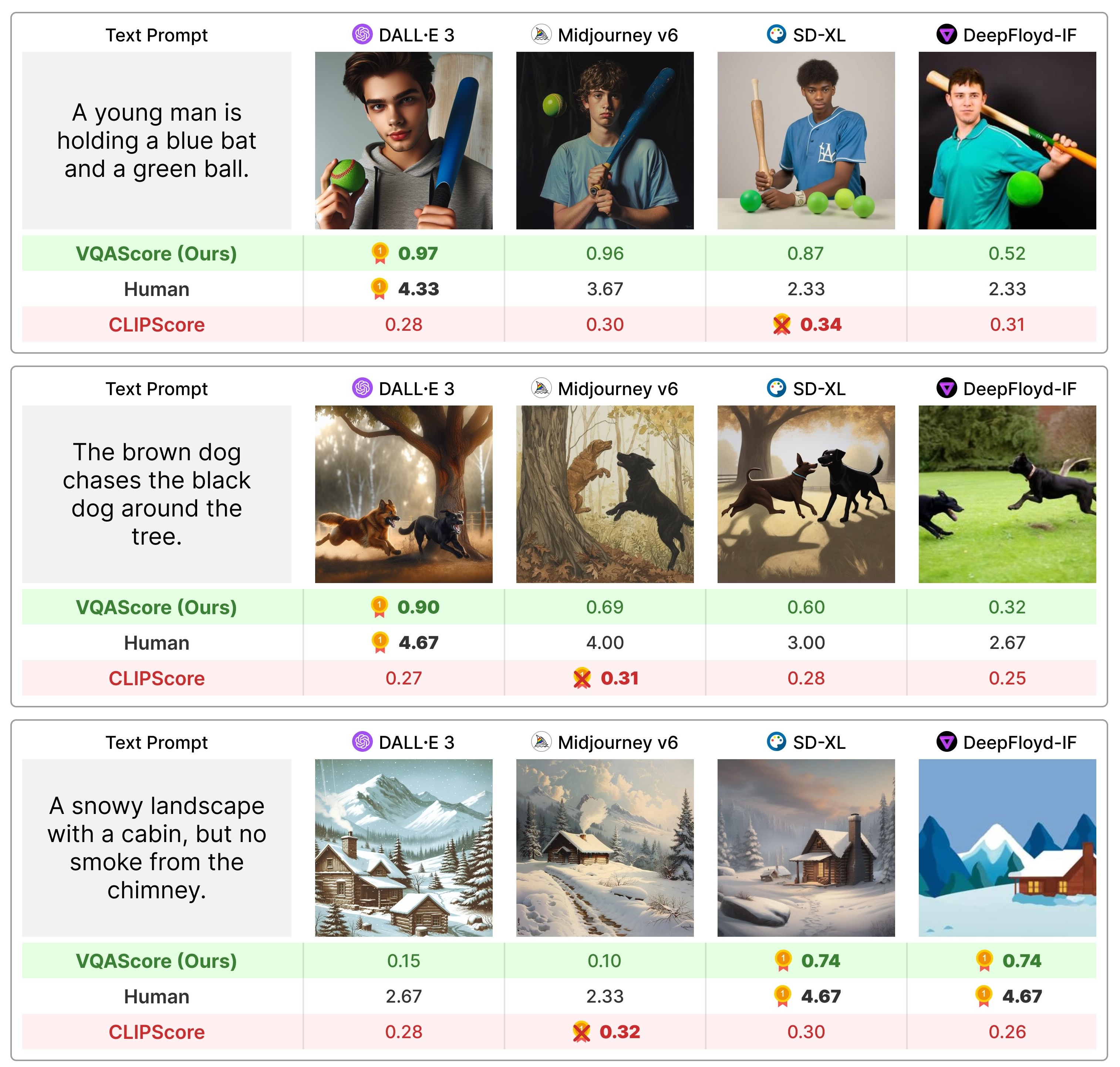
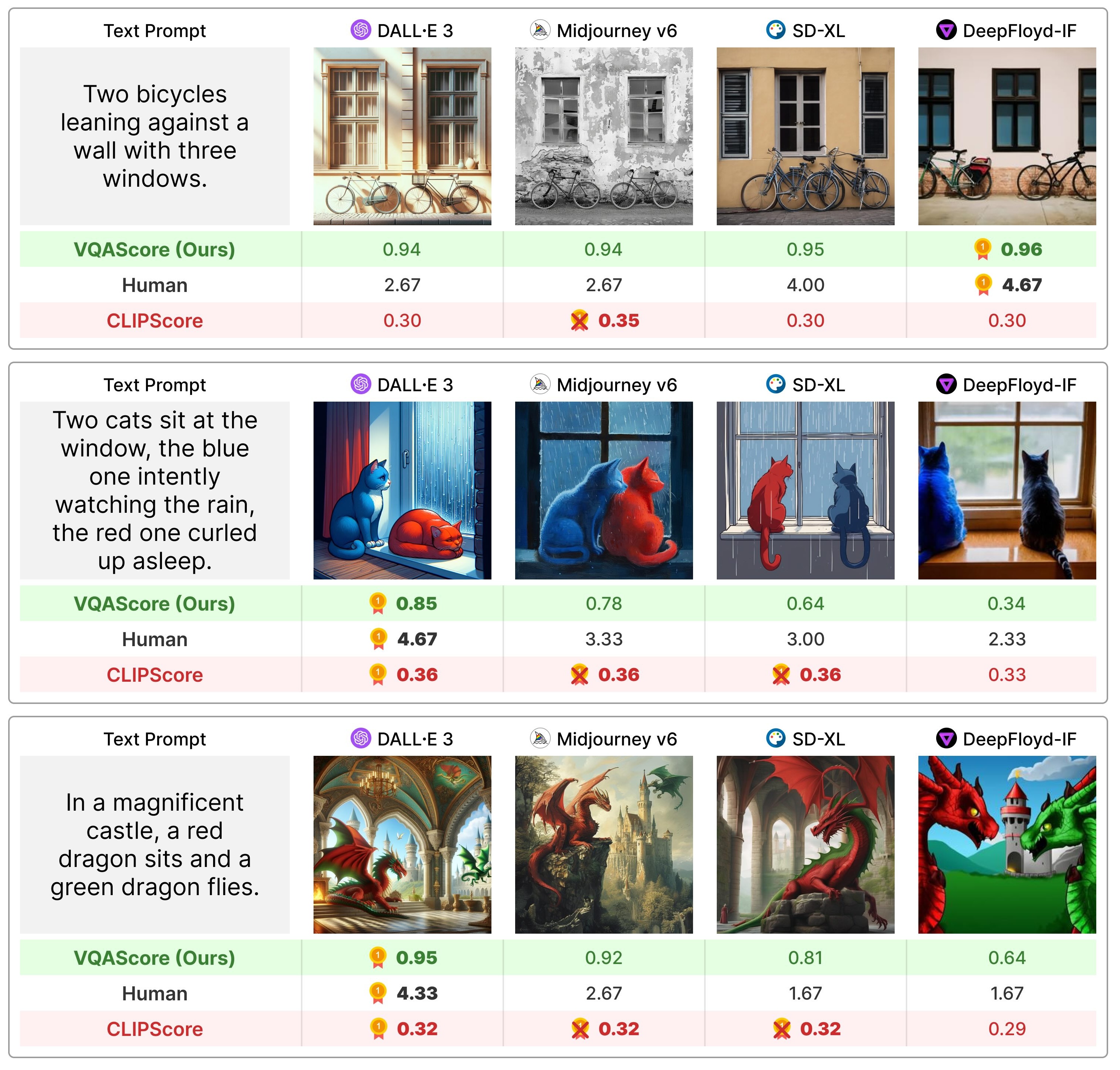
Compared to the bag-of-words CLIPScore (in red), VQAScore (in green) based on our CLIP-FlanT5 model correlates better with human judgments on images generated from compositional text prompts that involve attribute bindings, spatial/action/part relations, and higher-order reasoning such as negation and comparison.