Three contributions: a structured retrieval method that matches generative reranker quality at scale, the largest cinematic taxonomy to date (CameraBench-Pro), and a 50K-query benchmark covering single keywords through 400-word cinematic scripts in English and Chinese.
Method · Structured Retrieval Five aspects, encoded separately, max-pooled at query time
Each video is captioned along five aspects — subject, scene, motion, spatial, camera — and each caption is encoded into its own Qwen3-Embedding-8B vector. At query time we embed the user query once and score each video by the max cosine similarity across its five vectors, so the query aligns to whichever aspect it most directly targets. All vectors are pre-indexed offline.
| Strategy | Caption Source | Caption Type | Scalable | Time/Query | Hit | MRR@10 | ||
|---|---|---|---|---|---|---|---|---|
| @1 | @5 | @10 | ||||||
| Off-the-shelf models | ||||||||
| Gemini Embedding 2 | — | — | ✓ | — | — | — | — | — |
| Qwen3-VL Embedding | — | — | ✓ | — | — | — | — | — |
| Qwen3-VL Reranker | — | — | ✗ | — | — | — | — | — |
| Qwen3 Embedding | Qwen3-VL | Single-Caption | ✓ | — | — | — | — | — |
| Qwen3 Embedding | Qwen3-VL | Structured-Caption | ✓ | — | — | — | — | — |
| Using Qwen3-VL-SFT captions (ours) | ||||||||
| Qwen3 Embedding | Qwen3-VL-SFT | Single-Caption | ✓ | — | — | — | — | — |
| Qwen3 Embedding | Qwen3-VL-SFT | Structured-Caption | ✓ | — | — | — | — | — |
Table 1. Retrieval on the Moodio-T2V benchmark. Our 5-aspect structured-caption retrieval (highlighted) outperforms embedding baselines (Gemini Embedding 2, Qwen3-VL Embedding) and matches Qwen3-VL Reranker quality orders of magnitude faster, since Reranker requires a forward pass per (video, query) pair and is infeasible at million-video scale. Numbers will be filled in upon release.
Data · CameraBench-Pro 225 cinematic primitives across 17 skill categories
The largest professionally-annotated cinematic video understanding dataset to date — a 4× expansion of CameraBench (NeurIPS '25 Spotlight) from camera motion to the full language of cinema. Co-designed with 100+ professional filmmakers over a year.
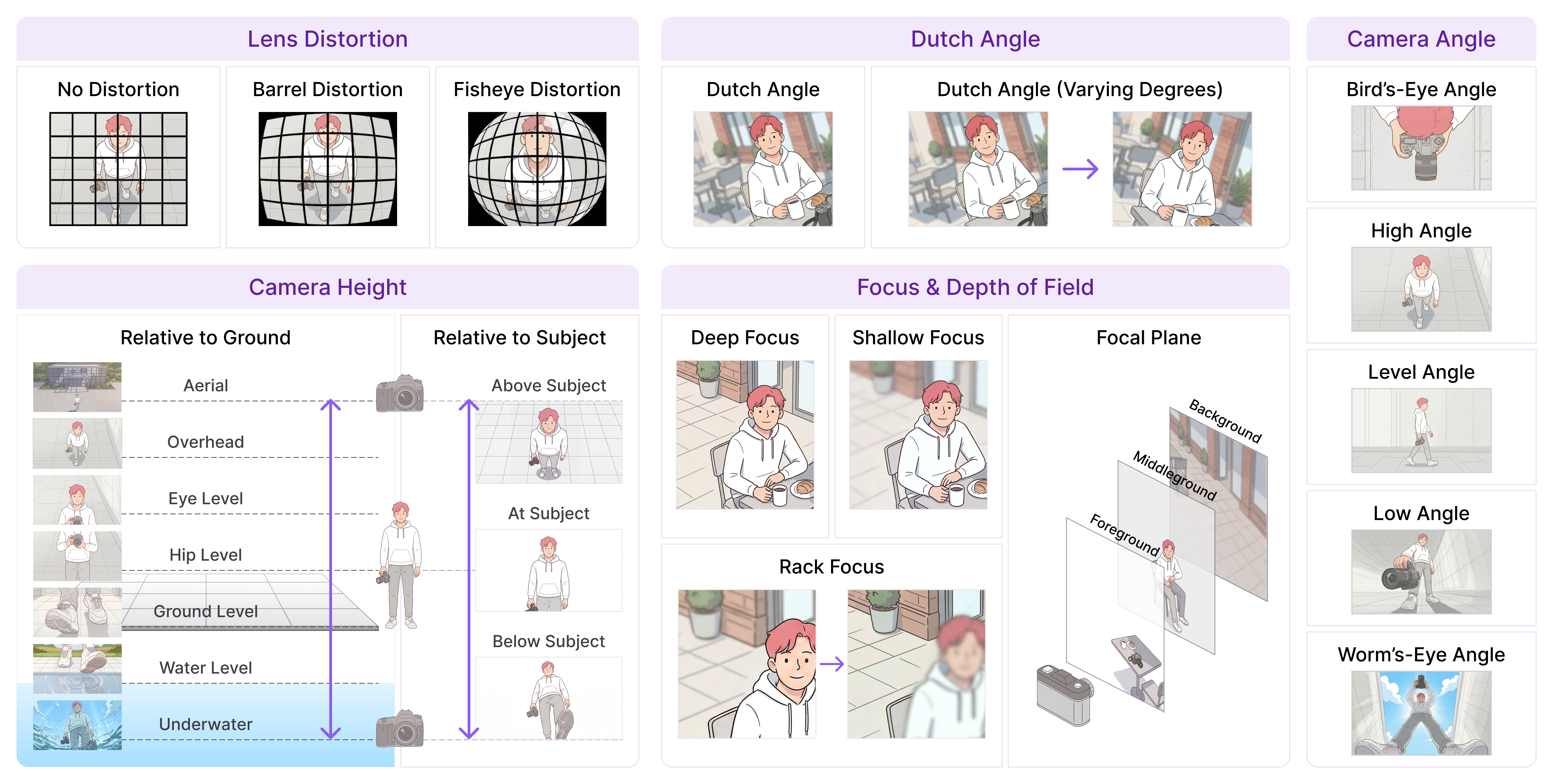
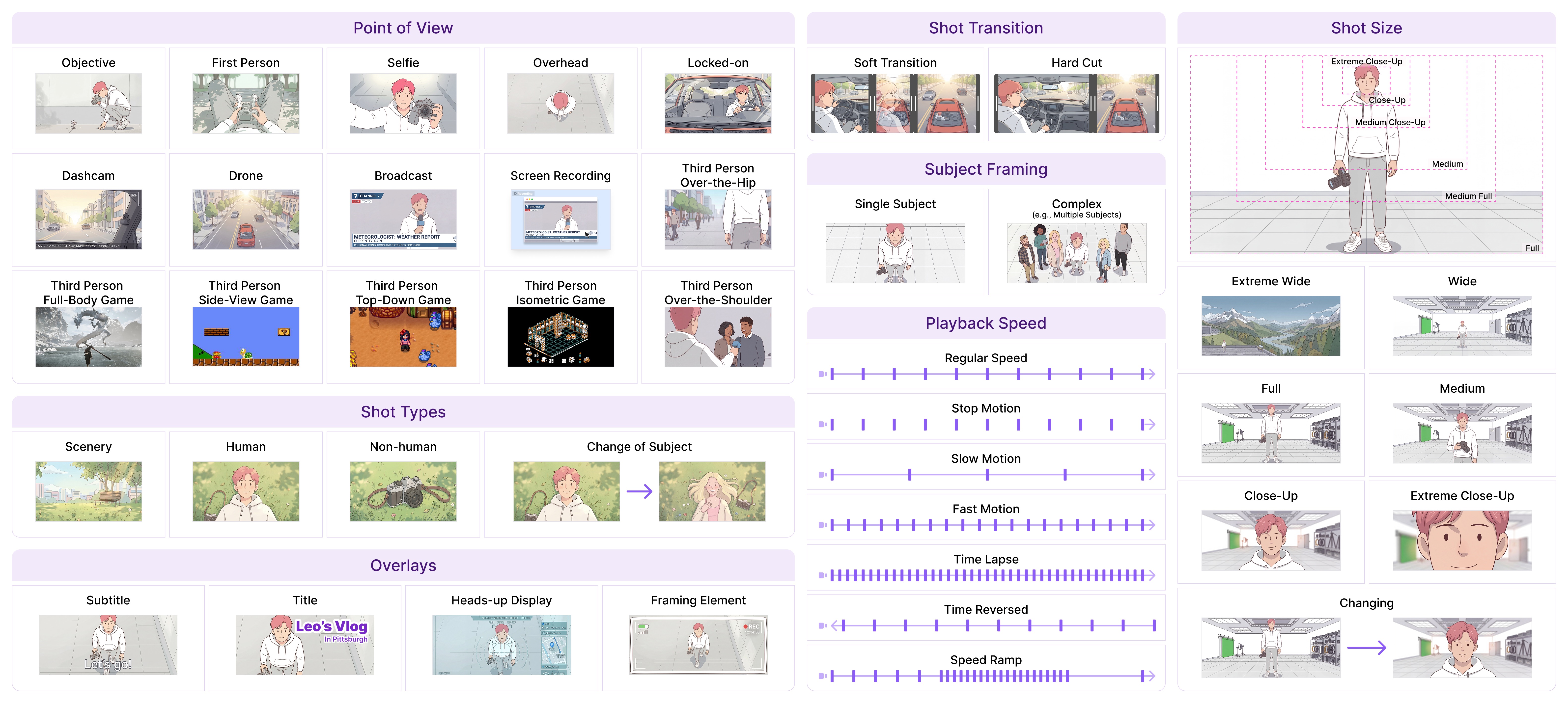
Figure 5. Excerpts from the CameraBench-Pro taxonomy. Left: camera-side primitives (lens distortion, Dutch angle, camera angle, camera height, focus & depth of field). Right: scene-side primitives (point of view, shot types, shot transitions, subject framing, playback speed, shot size, overlays).
Evaluation · Moodio-T2V Benchmark 50K bilingual queries, simulated from real creator search behavior
Prior text-to-video benchmarks (MSR-VTT, LSMDC, DiDeMo) use short, stylistically uniform English queries with one-to-one query-video mappings. Moodio-T2V instead spans single keywords through 400-word cinematic descriptions across four framings (concise / question / request / verbose) and two languages — with pooled relevance sets so multiple videos can satisfy the same intent.
Figure 6. The Moodio-T2V query simulator. Each held-out video is decomposed into a grounded 5-aspect caption, sampled into structured query contents, then rendered into eight surface forms (concise / question / request / verbose × EN / ZH) — yielding 50K diverse queries.