We built a language of cinema for AI in four pieces: a structured specification for what to describe, a scalable human–AI oversight framework for how to annotate it at quality, post-training recipes that turn those annotations into a model that beats GPT-5 and Gemini-3.1, and a re-captioned video corpus that unlocks professional-level video generation.
Precise Specification
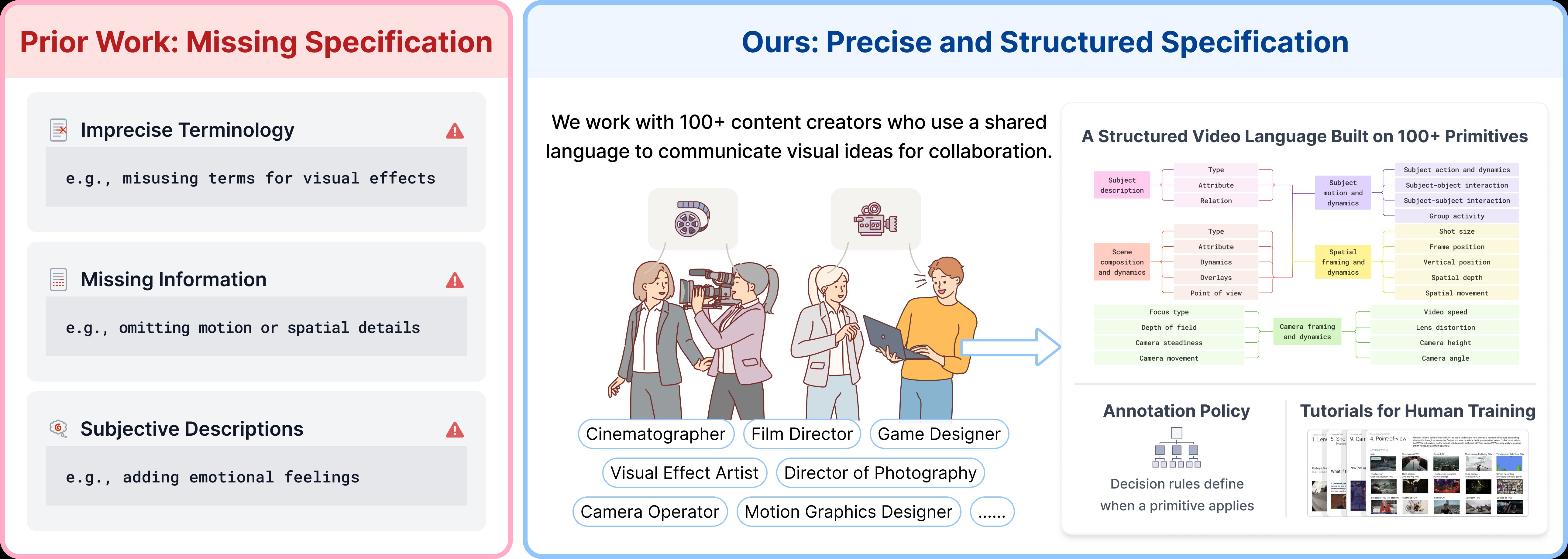
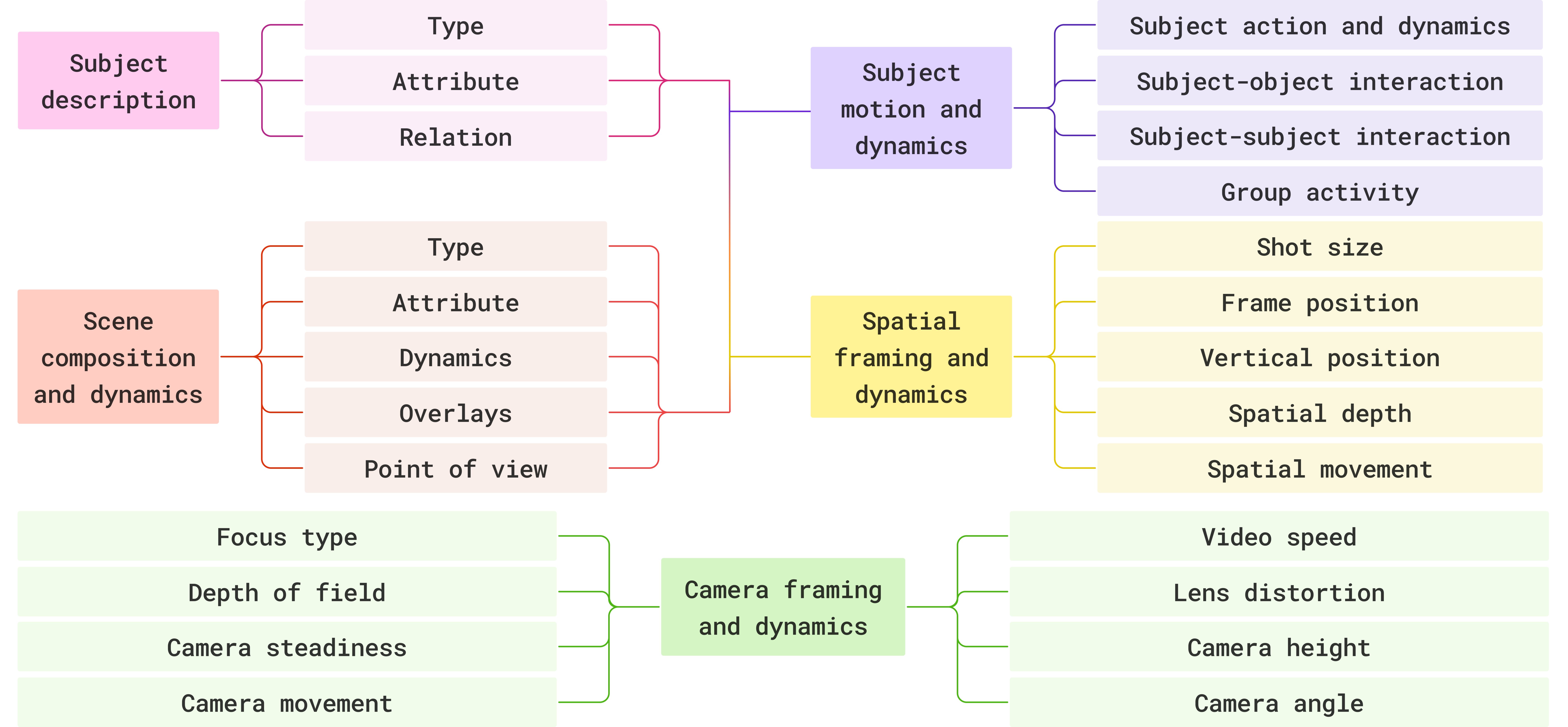
A structured video language spanning subjects, scenes, motion, spatial framing, and camera dynamics — grounded by 200+ visual primitives co-designed with professional cinematographers.
Scalable Oversight
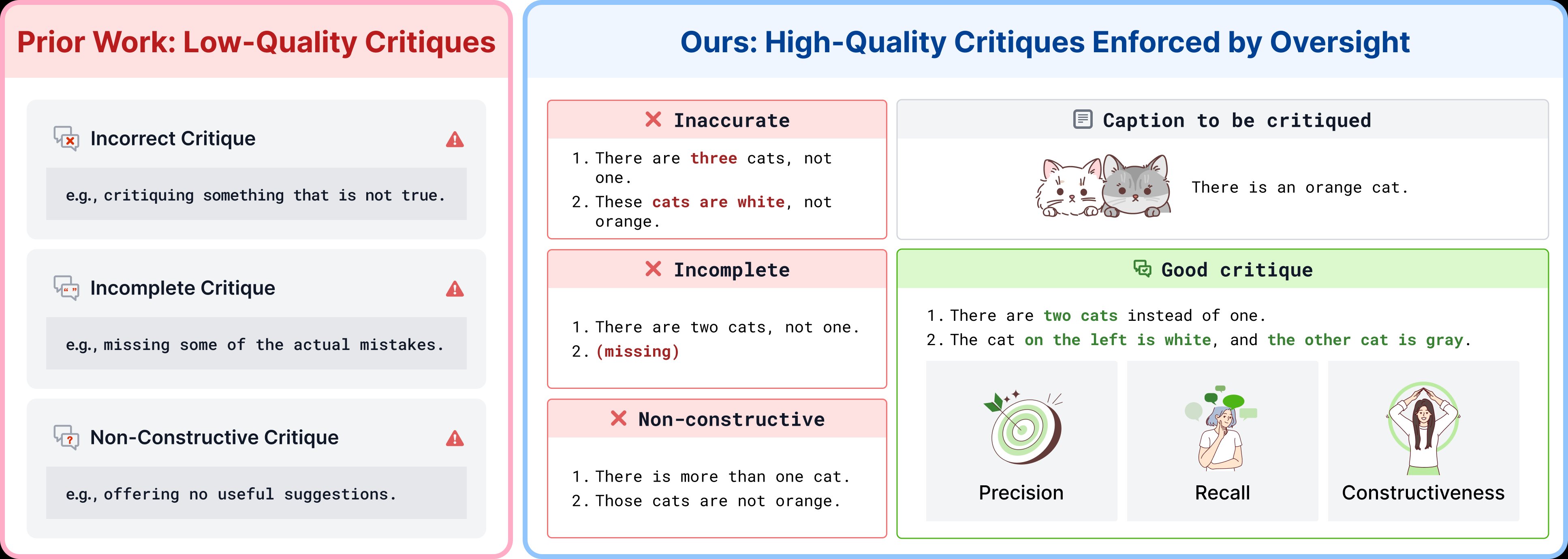
LLMs write more fluently than most humans, but hallucinate what they see. CHAI lets AI draft captions and humans critique — shifting effort from generation to verification.
Post-Training
Our Qwen3-VL-8B surpasses Gemini-3.1 and GPT-5. Human critiques turn AI drafts into accurate captions, yielding signals for SFT, DPO, reward modeling, and inference-time scaling.
Better Generation
We fine-tune Wan to follow our detailed cinematic prompts of up to 400 words — precise control over dolly zoom, rack focus, speed ramps, Dutch angles, POVs, and more.
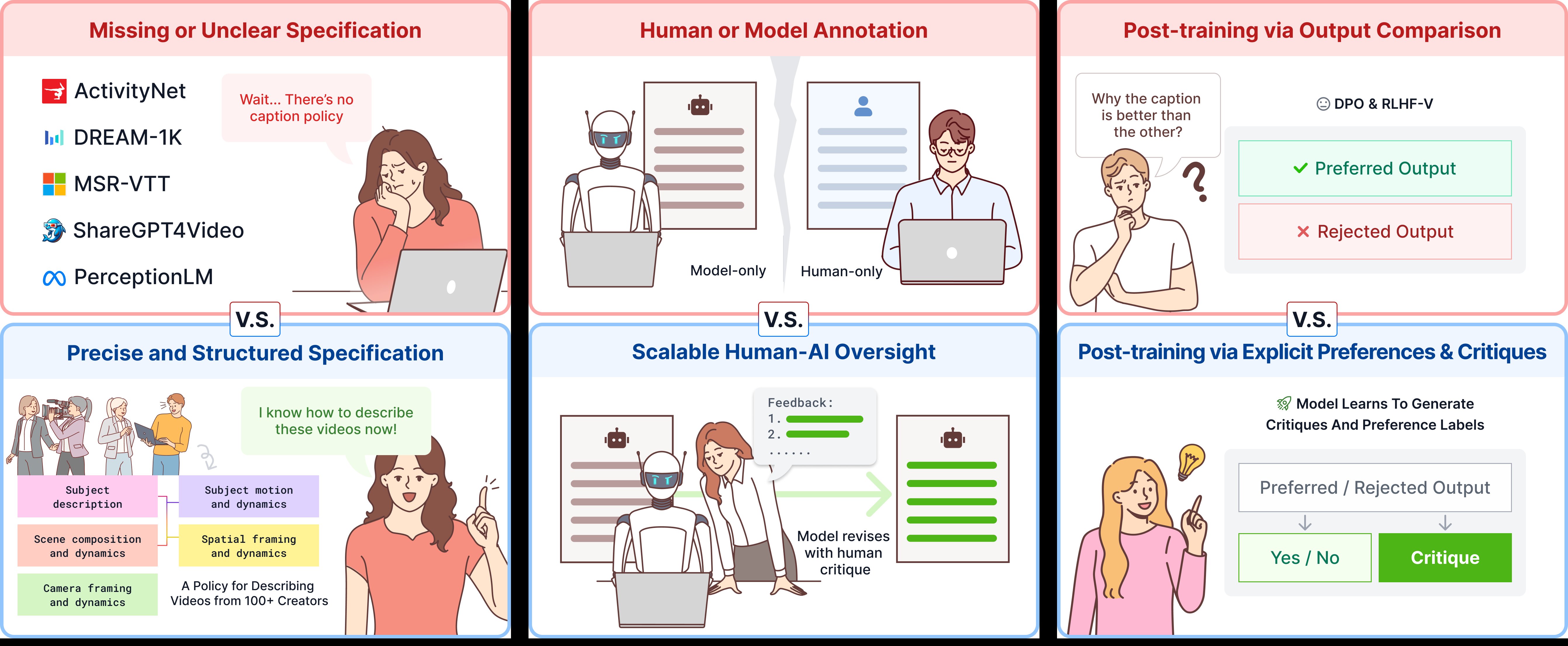
Figure 1. Our recipe for precise video language. Red (top): prior work lacks specification and oversight, leading to imprecise terminology, hallucinations, and poor writing. Blue (bottom): CHAI combines structured specification, critique-based oversight, and post-training — which in turn unlock professional-quality video generation.